Table of Contents
Introduction
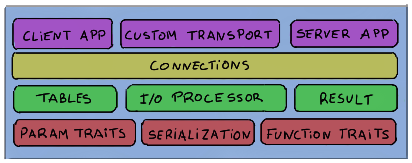
This article explores a C++ RPC framework I’ve been working on which requires no code generation step for glue code.
Before I start rambling on implementation details, and so you know what to expect, here is a feature list:
- Source available at https://bitbucket.org/ruifig/czrpc
- The source code shown in this article is by no means complete. It’s meant to show the foundations upon which the framework was built. Also, to shorten things a bit, it’s a mix of code from the repository at the time of writing and custom sample code, so it might have errors.
- Some of the source code which is not directly related to the problem at hand is left intentionally simple with disregard for performance. Any improvements will later be added to source code repository.
- Modern C++ (C++11/14)
- Requires at least Visual Studio 2015. Clang/GCC is fine too, but might not work as-is, since VS is less strict.
- Type-safe
- The framework detects at compile time invalid RPC calls, such as unknown RPC names, wrong number of parameters, or wrong parameter types.
- Relatively small API and not too verbose (considering it requires no code generation)
- Multiple ways to handle RPC replies
- Asynchronous handler
- Futures
- A client can detect if an RPC caused an exception server side
- Allows the use of potentially any type in RPC parameters
- Provided the user implements the required functions to deal with that type.
- Bidirectional RPCs (A server can call RPCs on a client)
- Typically, client code cannot be trusted, but since the framework is to be used between trusted parties, this is not a problem.
- Non intrusive
- An object being used for RPC calls doesn’t need to know anything about RPCs or network.
- This makes it possible to wrap third party classes for RPC calls.
- Minimal bandwidth overhead per RPC call
- No external dependencies
- Although the supplied transport (in the source code repository) uses Asio/Boost Asio, the framework itself does not depend on it. You can plug in your own transport.
- No security features provided
- Because the framework is intended to be used between trusted parties (e.g: between servers).
- The application can specify its own transport, therefore having a chance to encrypt anything if required.
Even though the source code shown is not complete, the article is still very heavy on code.
Code is presented in small portions and every section builds on the previous, but is still an overwhelming amount of code.
So that you have an idea of how it will look like in the end, here is a fully functional sample using the source code repository at the time of writing:
//////////////////////////////////////////////////////////////////////////
// Useless RPC-agnostic class that performs calculations.
//////////////////////////////////////////////////////////////////////////
class Calculator {
public:
double add(double a, double b) { return a + b; }
};
//////////////////////////////////////////////////////////////////////////
// Define the RPC table for the Calculator class
// This needs to be seen by both the server and client code
//////////////////////////////////////////////////////////////////////////
#define RPCTABLE_CLASS Calculator
#define RPCTABLE_CONTENTS \
REGISTERRPC(add)
#include "crazygaze/rpc/RPCGenerate.h"
//////////////////////////////////////////////////////////////////////////
// A Server that only accepts 1 client, then shuts down
// when the client disconnects
//////////////////////////////////////////////////////////////////////////
void RunServer() {
asio::io_service io;
// Start thread to run Asio's the io_service
// we will be using for the server
std::thread th = std::thread([&io] {
asio::io_service::work w(io);
io.run();
});
// Instance we will be using to serve RPC calls.
// Note that it's an object that knows nothing about RPCs
Calculator calc;
// start listening for a client connection.
// We specify what Calculator instance clients will use,
auto acceptor = AsioTransportAcceptor<Calculator, void>::create(io, calc);
// Start listening on port 9000.
// For simplicity, we are only expecting 1 client
using ConType = Connection<Calculator, void>;
std::shared_ptr<ConType> con;
acceptor->start(9000, [&io, &con](std::shared_ptr<ConType> con_) {
con = con_;
// Since this is just a sample, close the server once the first client
// disconnects
reinterpret_cast<BaseAsioTransport*>(con->transport.get())
->setOnClosed([&io] { io.stop(); });
});
th.join();
}
//////////////////////////////////////////////////////////////////////////
// A client that connects to the server, calls 1 RPC
// then disconnects, causing everything to shut down
//////////////////////////////////////////////////////////////////////////
void RunClient() {
// Start a thread to run our Asio io_service
asio::io_service io;
std::thread th = std::thread([&io] {
asio::io_service::work w(io);
io.run();
});
// Connect to the server (localhost, port 9000)
auto con =
AsioTransport<void, Calculator>::create(io, "127.0.0.1", 9000).get();
// Call one RPC (the add method), specifying an asynchronous handler for
// when the result arrives
CZRPC_CALL(*con, add, 1, 2)
.async([&io](Result<double> res) {
printf("Result=%f\n", res.get()); // Prints 3.0
// Since this is a just a sample, stop the io_service after we get
// the result,
// so everything shuts down
io.stop();
});
th.join();
}
// For testing simplicity, run both the server and client on the same machine,
void RunServerAndClient() {
auto a = std::thread([] { RunServer(); });
auto b = std::thread([] { RunClient(); });
a.join();
b.join();
}
This code is mostly setup code, since the provided transport uses Asio.
The RPC calls itself can be as simple as:
// RPC call using asynchronous handler to handle the result
CZRPC_CALL(*con, add, 1, 2).async([](Result<double> res) {
printf("Result=%f\n", res.get()); // Prints 3.0
});
// RPC call using std::future to handle the result
Result<double> res = CZRPC_CALL(*con, add, 1, 2).ft().get();
printf("Result=%f\n", res.get()); // Prints 3.0
Why I needed this
The game I’ve been working on for a couple of years now (code named G4), gives players fully simulated little in-game computers they can code for whatever they want.
That requires me to have a couple of server types running:
- Gameplay Server(s)
- VM Server(s) (Simulates the in-game computers)
- So that in-game computers can be simulated even if the player is not currently online
- VM Disk Server(s)
- Deals with in-game computer’s storage, like floppies or hard drives.
- Database server(s)
- Login server(s)
All these servers need to exchange data, therefore the need for a flexible RPC framework.
Initially I had a custom solution where I would tag methods of a class with certain attributes, then have a Clang based parser (clReflect) generate any required serialization and glue code.
Although it worked fine for the most part, for the past year or so I kept wondering how could I use the new C++11/14 features to create a minimal type safe C++ RPC framework.
Something that would not need a code generation step for glue code, while still keeping an acceptable API.
For serialization of non-fundamental types, code generation is still useful, so I don’t need to manually define how to serialize all the fields of a given struct/class. Although defining those manually is not a big deal, I believe.
RPC Parameters
Given a function, in order to have type safe RPC calls, there are a few things we need to be able to do:
- Identify at compile time if this function is a valid RPC function (Right number of parameters, right type of parameters, etc)
- Check if the supplied parameters match (or can be converted) to what the function signature specifies.
- Serialize all parameters
- Deserialize all parameters
- Call the desired function
Parameter Traits
The first problem you’ll face is in deciding what type of parameters are accepted. Some RPC frameworks only accept a limited number of types, such as Thrift. Let’s check the problem.
Given these function signatures:
void func1(int a, float b, char c); void func2(const char* a, std::string b, const std::string& c); void func3(Foo a, Bar* b);
How can we make compile time checks regarding the parameters?
Fundamental types are easy enough and should definitely be supported by the framework. A dumb memory copy will do the trick in those cases unless you want to trade a bit of performance for bandwidth usage by cutting down the number of bits needed.
But how about complex types such std::string, std::vector, or your own classes?
How about pointers, references, const references, rvalues?
We can get some inspiration from what the C++ Standard Library does in the type_traits header.
We need to be able to query a given type regarding its RPC properties. Let’s put that concept in a template class ParamTraits<T>, with the following layout .
| Member constants | |
|---|---|
valid |
true if T is valid for RPC parameters, false otherwise |
| Member types | |
store_type |
Type used to hold the temporary copy needed when deserializing |
| Member functions | |
write |
Writes the parameter to a stream |
read |
Reads a parameter into a store_type |
get |
Given a store_type parameter, it returns what can be passed to the RPC function as a parameter |
As an example, let’s implement ParamTraits<T> for arithmetic types, considering we have a stream class with a write and read methods:
namespace cz {
namespace rpc {
// By default, all types for which ParamTraits is not specialized are invalid
template <typename T, typename ENABLED = void>
struct ParamTraits {
using store_type = int;
static constexpr bool valid = false;
};
// Specialization for arithmetic types
template <typename T>
struct ParamTraits<
T, typename std::enable_if<std::is_arithmetic<T>::value>::type> {
using store_type = typename std::decay<T>::type;
static constexpr bool valid = true;
template <typename S>
static void write(S& s, typename std::decay<T>::type v) {
s.write(&v, sizeof(v));
}
template <typename S>
static void read(S& s, store_type& v) {
s.read(&v, sizeof(v));
}
static store_type get(store_type v) {
return v;
}
};
} // namespace rpc
} // namespace cz
And a simple test:
#define TEST(exp) printf("%s = %s\n", #exp, exp ? "true" : "false");
void testArithmetic() {
TEST(ParamTraits<int>::valid); // true
TEST(ParamTraits<const int>::valid); // true
TEST(ParamTraits<int&>::valid); // false
TEST(ParamTraits<const int&>::valid); // false
}
ParamTraits<T> is also used to check if return types are valid, and since a void function is valid, we need to specialize ParamTraits for void too.
namespace cz {
namespace rpc {
// void type is valid
template <>
struct ParamTraits<void> {
static constexpr bool valid = true;
using store_type = void;
};
} // namespace rpc
} // namespace cz
The apparently strange thing with the specialization for void is that it also specifies a store_type. We can’t use it to store anything, but will make some of the later template code easier.
With these ParamTraits examples, references are not valid RPC parameters. In practice you do want to allow const references at least, especially for fundamental types. A tweak can be added to enable support for const T& for any valid T if your application needs it.
// Make "const T&" valid for any valid T
#define CZRPC_ALLOW_CONST_LVALUE_REFS \
namespace cz { \
namespace rpc { \
template <typename T> \
struct ParamTraits<const T&> : ParamTraits<T> { \
static_assert(ParamTraits<T>::valid, \
"Invalid RPC parameter type. Specialize ParamTraits if " \
"required."); \
}; \
} \
}
Similar tweaks can be made to enable support for T& or T&& if required, although if the function makes changes to those parameters, those changes will be lost.
Let’s try adding support for a complex type, such as std::vector<T>. For std::vector<T> to be supported, T needs to be supported too.
namespace cz {
namespace rpc {
template <typename T>
struct ParamTraits<std::vector<T>> {
using store_type = std::vector<T>;
static constexpr bool valid = ParamTraits<T>::valid;
static_assert(ParamTraits<T>::valid == true,
"T is not valid RPC parameter type.");
// std::vector serialization is done by writing the vector size, followed by
// each element
template <typename S>
static void write(S& s, const std::vector<T>& v) {
int len = static_cast<int>(v.size());
s.write(&len, sizeof(len));
for (auto&& i : v) ParamTraits<T>::write(s, i);
}
template <typename S>
static void read(S& s, std::vector<T>& v) {
int len;
s.read(&len, sizeof(len));
v.clear();
while (len--) {
T i;
ParamTraits<T>::read(s, i);
v.push_back(std::move(i));
}
}
static std::vector<T>&& get(std::vector<T>&& v) {
return std::move(v);
}
};
} // namespace rpc
} // namespace cz
// A simple test
void testVector() {
TEST(ParamTraits<std::vector<int>>::valid); // true
// true if support for const refs was enabled
TEST(ParamTraits<const std::vector<int>&>::valid);
}
For convenience, we can use the << and >> operators with Stream class (not shown here). Those operators simply call the respective ParamTraits<T> read and write functions.
Now that we can check if a specific type is allowed for RPC parameters, we can build on that and check if a function can be used for RPCs. This is implemented with variadic templates.
First let’s create a template to tells us if a bunch of parameters are valid.
namespace cz {
namespace rpc {
//
// Validate if all parameter types in a parameter pack can be used for RPC
// calls
//
template <typename... T>
struct ParamPack {
static constexpr bool valid = true;
};
template <typename First>
struct ParamPack<First> {
static constexpr bool valid = ParamTraits<First>::valid;
};
template <typename First, typename... Rest>
struct ParamPack<First, Rest...> {
static constexpr bool valid =
ParamTraits<First>::valid && ParamPack<Rest...>::valid;
}
} // namespace rpc
} // namespace cz
// Usage example:
void testParamPack() {
TEST(ParamPack<>::valid); // true (No parameters is a valid too)
TEST((ParamPack<int, double>::valid)); // true
TEST((ParamPack<int, int*>::valid)); // false
}
Using ParamPack, we can now create a FunctionTraits template to query a function’s properties.
namespace cz {
namespace rpc {
template <class F>
struct FunctionTraits {};
// For free function pointers
template <class R, class... Args>
struct FunctionTraits<R (*)(Args...)> : public FunctionTraits<R(Args...)> {};
// For method pointers
template <class R, class C, class... Args>
struct FunctionTraits<R (C::*)(Args...)> : public FunctionTraits<R(Args...)> {
using class_type = C;
};
// For const method pointers
template <class R, class C, class... Args>
struct FunctionTraits<R (C::*)(Args...) const>
: public FunctionTraits<R(Args...)> {
using class_type = C;
};
template <class R, class... Args>
struct FunctionTraits<R(Args...)> {
// Tells if both the return type and parameters are valid for RPC calls
static constexpr bool valid =
ParamTraits<R>::valid && ParamPack<Args...>::valid;
using return_type = R;
// Number of parameters
static constexpr std::size_t arity = sizeof...(Args);
// A tuple that can store all parameters
using param_tuple = std::tuple<typename ParamTraits<Args>::store_type...>;
// Allows us to get the type of each parameter, given an index
template <std::size_t N>
struct argument {
static_assert(N < arity, "error: invalid parameter index.");
using type = typename std::tuple_element<N, std::tuple<Args...>>::type;
};
};
} // namespace rpc
} // namespace cz
// A simple test...
struct FuncTraitsTest {
void func1() const {}
void func2(int) {}
int func3(const std::vector<int>&) { return 0; }
int* func4() { return 0; }
};
void testFunctionTraits() {
TEST(FunctionTraits<decltype(&FuncTraitsTest::func1)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func2)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func3)>::valid); // true
TEST(FunctionTraits<decltype(&FuncTraitsTest::func4)>::valid); // false
}
FunctionTraits gives us a couple of properties that will be used later. Note for example that FunctionTraits::param_tuple builds on ParamTraits<T>::store_type . This is needed, since at some point we need a way to deserialize all parameters into a tuple before calling the function.
Serialization
Since we now have the required code for querying parameters, return types and validating functions, we can put together the code to serialize a function call.
Also, it is type safe. It will not compile if given the wrong number or type of parameters, or if the function itself is not valid for RPCs (e.g: unsupported return/parameter types).
namespace cz {
namespace rpc {
namespace details {
template <typename F, int N>
struct Parameters {
template <typename S>
static void serialize(S&) {}
template <typename S, typename First, typename... Rest>
static void serialize(S& s, First&& first, Rest&&... rest) {
using Traits =
ParamTraits<typename FunctionTraits<F>::template argument<N>::type>;
Traits::write(s, std::forward<First>(first));
Parameters<F, N + 1>::serialize(s, std::forward<Rest>(rest)...);
}
};
} // namespace details
template <typename F, typename... Args>
void serializeMethod(Stream& s, Args&&... args) {
using Traits = FunctionTraits<F>;
static_assert(Traits::valid,
"Function signature not valid for RPC calls. Check if "
"parameter types are valid");
static_assert(Traits::arity == sizeof...(Args),
"Invalid number of parameters for RPC call.");
details::Parameters<F, 0>::serialize(s, std::forward<Args>(args)...);
}
} // namespace rpc
} // namespace cz
//
// A simple test
//
struct SerializeTest {
void func1(int, const std::vector<int>) {}
void func2(int*) {}
};
void testSerializeCall() {
Stream s;
serializeMethod<decltype(&SerializeTest::func1)>(s, 1,
std::vector<int>{1, 2, 3});
// These fail to compile because of the wrong number of parameters
// serializeMethod<decltype(&SerializeTest::func1)>(s);
// serializeMethod<decltype(&SerializeTest::func1)>(s, 1);
// Doesn't compile because of wrong type of parameters
// serializeMethod<decltype(&SerializeTest::func1)>(s, 1, 2);
// Doesn't compile because the function can't be used for RPCs.
// int a;
// serializeMethod<decltype(&SerializeTest::func2)>(s, &a);
}
Deserialization
As mentioned above, FunctionTraits<F>::param_tuple is the std::tuple type we can use to hold all the function’s parameters. In order to be able to use this tuple to deserialize parameters, we need to specialize ParamTraits for tuples.
This has the nice side effect of also making it possible to use std::tuple for RPC parameters.
namespace cz {
namespace rpc {
namespace details {
template <typename T, bool Done, int N>
struct Tuple {
template <typename S>
static void deserialize(S& s, T& v) {
s >> std::get<N>(v);
Tuple<T, N == std::tuple_size<T>::value - 1, N + 1>::deserialize(s, v);
}
template <typename S>
static void serialize(S& s, const T& v) {
s << std::get<N>(v);
Tuple<T, N == std::tuple_size<T>::value - 1, N + 1>::serialize(s, v);
}
};
template <typename T, int N>
struct Tuple<T, true, N> {
template <typename S>
static void deserialize(S&, T&) {}
template <typename S>
static void serialize(S&, const T&) {}
};
} // namespace details
template <typename... T>
struct ParamTraits<std::tuple<T...>> {
using tuple_type = std::tuple<T...>; // for internal use
using store_type = tuple_type;
static constexpr bool valid = ParamPack<T...>::valid;
static_assert(
ParamPack<T...>::valid == true,
"One or more tuple elements is not a valid RPC parameter type.");
template <typename S>
static void write(S& s, const tuple_type& v) {
details::Tuple<tuple_type, std::tuple_size<tuple_type>::value == 0,
0>::serialize(s, v);
}
template <typename S>
static void read(S& s, tuple_type& v) {
details::Tuple<tuple_type, std::tuple_size<tuple_type>::value == 0,
0>::deserialize(s, v);
}
static tuple_type&& get(tuple_type&& v) {
return std::move(v);
}
};
} // namespace rpc
} // namespace cz
// A simple test
void testDeserialization() {
Stream s;
serializeMethod<decltype(&SerializeTest::func1)>(s, 1,
std::vector<int>{1, 2});
// deserialize the parameters into a tuple.
// the tuple is of type std::tuple<int,std::vector<int>>
FunctionTraits<decltype(&SerializeTest::func1)>::param_tuple params;
s >> params;
};
From tuple to function parameters
After we deserialize all the parameters into a tuple, we now need to figure out how to unpack the tuple to call a matching function. This is once again done with variadic templates.
namespace cz {
namespace rpc {
namespace detail {
template <typename F, typename Tuple, bool Done, int Total, int... N>
struct callmethod_impl {
static decltype(auto) call(typename FunctionTraits<F>::class_type& obj, F f,
Tuple&& t) {
return callmethod_impl<F, Tuple, Total == 1 + sizeof...(N), Total, N...,
sizeof...(N)>::call(obj, f,
std::forward<Tuple>(t));
}
};
template <typename F, typename Tuple, int Total, int... N>
struct callmethod_impl<F, Tuple, true, Total, N...> {
static decltype(auto) call(typename FunctionTraits<F>::class_type& obj, F f,
Tuple&& t) {
using Traits = FunctionTraits<F>;
return (obj.*f)(
ParamTraits<typename Traits::template argument<N>::type>::get(
std::get<N>(std::forward<Tuple>(t)))...);
}
};
} // namespace details
template <typename F, typename Tuple>
decltype(auto) callMethod(typename FunctionTraits<F>::class_type& obj, F f,
Tuple&& t) {
static_assert(FunctionTraits<F>::valid, "Function not usable as RPC");
typedef typename std::decay<Tuple>::type ttype;
return detail::callmethod_impl<
F, Tuple, 0 == std::tuple_size<ttype>::value,
std::tuple_size<ttype>::value>::call(obj, f, std::forward<Tuple>(t));
}
} // namespace rpc
} // namespace cz
// A simple test
void testCall() {
Stream s;
// serialize
serializeMethod<decltype(&SerializeTest::func1)>(s, 1,
std::vector<int>{1, 2});
// deserialize
FunctionTraits<decltype(&SerializeTest::func1)>::param_tuple params;
s >> params;
// Call func1 on an object, unpacking the tuple into parameters
SerializeTest obj;
callMethod(obj, &SerializeTest::func1, std::move(params));
};
So, we now know how to validate a function, serialize, deserialize, and call it. That’s the low level code done. The layer we’ll now build on top of this code will be the actual RPC API.
The RPC API
Header
The header contains the following information:

| Field | |
|---|---|
| size | Total size in bytes of the RPC. Having the size as part of the header greatly simplifies things, since we can check if we received all the data before trying to process the RPC. |
| counter | Call number. Every time we call an RPC, a counter is incremented and assigned to that RPC call. |
| rpcid | The function to call |
| isReply | If true, it’s a reply to an RPC. If false, it’s an RPC call. |
| success | This only applies to replies (isReply==true). If true, the call was successful and the data is the reply. If false, the data is the exception information |
The counter and rpcid form a key that identifies an RPC call instance. This is needed to match an incoming RPC reply to the RPC call that caused it.
namespace cz {
namespace rpc {
// Small utility struct to make it easier to work with the RPC headers
struct Header {
enum {
kSizeBits = 32,
kRPCIdBits = 8,
kCounterBits = 22,
};
explicit Header() {
static_assert(sizeof(*this) == sizeof(uint64_t),
"Invalid size. Check the bitfields");
all_ = 0;
}
struct Bits {
unsigned size : kSizeBits;
unsigned counter : kCounterBits;
unsigned rpcid : kRPCIdBits;
unsigned isReply : 1; // Is it a reply to a RPC call ?
unsigned success : 1; // Was the RPC call a success ?
};
uint32_t key() const {
return (bits.counter << kRPCIdBits) | bits.rpcid;
}
union {
Bits bits;
uint64_t all_;
};
};
inline Stream& operator<<(Stream& s, const Header& v) {
s << v.all_;
return s;
}
inline Stream& operator>>(Stream& s, Header& v) {
s >> v.all_;
return s;
}
} // namespace rpc
} // namespace cz
Table
We already managed to serialize and deserialize an RPC, but not a way to map a serialized RPC to the right function on the server side.
To solve this, we need to assign an ID to each function. The client knows what function it wants to call and fills the header with the right ID. The server checks the header, and knowing the ID, it dispatches to the right handler.
Let’s create the basics to define such dispatching tables.
namespace cz {
namespace rpc {
//
// Helper code to dispatch a call.
namespace details {
// Handle RPCs with return values
template <typename R>
struct CallHelper {
template <typename OBJ, typename F, typename P>
static void impl(OBJ& obj, F f, P&& params, Stream& out) {
out << callMethod(obj, f, std::move(params));
}
};
// Handle void RPCs
template <>
struct CallHelper<void> {
template <typename OBJ, typename F, typename P>
static void impl(OBJ& obj, F f, P&& params, Stream& out) {
callMethod(obj, f, std::move(params));
}
};
}
struct BaseRPCInfo {
BaseRPCInfo() {}
virtual ~BaseRPCInfo(){};
std::string name;
};
class BaseTable {
public:
BaseTable() {}
virtual ~BaseTable() {}
bool isValid(uint32_t rpcid) const {
return rpcid < m_rpcs.size();
}
protected:
std::vector<std::unique_ptr<BaseRPCInfo>> m_rpcs;
};
template <typename T>
class TableImpl : public BaseTable {
public:
using Type = T;
struct RPCInfo : public BaseRPCInfo {
std::function<void(Type&, Stream& in, Stream& out)> dispatcher;
};
template <typename F>
void registerRPC(uint32_t rpcid, const char* name, F f) {
assert(rpcid == m_rpcs.size());
auto info = std::make_unique<RPCInfo>();
info->name = name;
info->dispatcher = [f](Type& obj, Stream& in, Stream& out) {
using Traits = FunctionTraits<F>;
typename Traits::param_tuple params;
in >> params;
using R = typename Traits::return_type;
details::CallHelper<R>::impl(obj, f, std::move(params), out);
};
m_rpcs.push_back(std::move(info));
}
};
template <typename T>
class Table : public TableImpl<T> {
static_assert(sizeof(T) == 0, "RPC Table not specified for the type.");
};
} // namespace rpc
} // namespace cz
The Table template needs to be specialized for the class we want to use for RPC calls.
Say we have a Calculator class we want to be able to use for RPC calls:
class Calculator {
public:
double add(double a, double b) {
m_ans = a + b;
return m_ans;
}
double sub(double a, double b) {
m_ans = a - b;
return m_ans;
}
double ans() {
return m_ans;
}
private:
double m_ans = 0;
};
We can specialize the Table template for Calculator, so both the client and server have something to work with :
// Table specialization for Calculator
template <>
class cz::rpc::Table<Calculator> : cz::rpc::TableImpl<Calculator> {
public:
enum class RPCId { add, sub, ans };
Table() {
registerRPC((int)RPCId::add, "add", &Calculator::add);
registerRPC((int)RPCId::sub, "sub", &Calculator::sub);
registerRPC((int)RPCId::ans, "ans", &Calculator::ans);
}
static const RPCInfo* get(uint32_t rpcid) {
static Table<Calculator> tbl;
assert(tbl.isValid(rpcid));
return static_cast<RPCInfo*>(tbl.m_rpcs[rpcid].get());
}
};
Given an ID, the get function returns the dispatcher for the right Calculator method. We can then pass our Calculator instance, input and output streams to the dispatcher, which takes care of the rest.
These specializations are quite verbose and error-prone, since the enums and the registerRPC calls need to match. But we can greatly shorten that with some macros.
But first, let’s see a verbose example on how to use this table :
void testCalculatorTable() {
// Both the client and server need to have access to the necessary table
using CalcT = Table<Calculator>;
//
// Client sends RPC
Stream toServer;
RPCHeader hdr;
hdr.bits.rpcid = (int)CalcT::RPCId::add;
toServer << hdr;
serializeMethod<decltype(&Calculator::add)>(toServer, 1.0, 9.0);
//
// Server receives RPC, and sends back a reply
Calculator calc; // object used to receive the RPCs
toServer >> hdr;
auto&& info = CalcT::get(hdr.bits.rpcid);
Stream toClient; // Stream for the reply
// Call the desired Calculator function.
info->dispatcher(calc, toServer, toClient);
//
// Client receives a reply
double r;
toClient >> r;
printf("%2.0f\n", r); // Will print "10"
}
Again, this is quite verbose, but its just to show the code flow. That will be improved later.
Now, how can we simplify the table specializations?
If we put the gist of tables specialization in an unguarded header, all you need is a couple of defines followed by an include of that unguarded header to generate what the equivalent of what we did manually.
Example:
#define RPCTABLE_CLASS Calculator
#define RPCTABLE_CONTENTS \
REGISTERRPC(add) \
REGISTERRPC(sub) \
REGISTERRPC(ans)
#include "RPCGenerate.h"
That’s surprisingly simple, no?
The RPCGenerate.h is an unguarded header that looks like this:
#ifndef RPCTABLE_CLASS
#error "Macro RPCTABLE_CLASS needs to be defined"
#endif
#ifndef RPCTABLE_CONTENTS
#error "Macro RPCTABLE_CONTENTS needs to be defined"
#endif
#define RPCTABLE_TOOMANYRPCS_STRINGIFY(arg) #arg
#define RPCTABLE_TOOMANYRPCS(arg) RPCTABLE_TOOMANYRPCS_STRINGIFY(arg)
template<> class cz::rpc::Table<RPCTABLE_CLASS> : cz::rpc::TableImpl<RPCTABLE_CLASS>
{
public:
using Type = RPCTABLE_CLASS;
#define REGISTERRPC(rpc) rpc,
enum class RPCId {
RPCTABLE_CONTENTS
NUMRPCS
};
Table()
{
static_assert((unsigned)((int)RPCId::NUMRPCS-1)<(1<<Header::kRPCIdBits),
RPCTABLE_TOOMANYRPCS(Too many RPCs registered for class RPCTABLE_CLASS));
#undef REGISTERRPC
#define REGISTERRPC(func) registerRPC((uint32_t)RPCId::func, #func, &Type::func);
RPCTABLE_CONTENTS
}
static const RPCInfo* get(uint32_t rpcid)
{
static Table<RPCTABLE_CLASS> tbl;
assert(tbl.isValid(rpcid));
return static_cast<RPCInfo*>(tbl.m_rpcs[rpcid].get());
}
};
#undef REGISTERRPC
#undef RPCTABLE_START
#undef RPCTABLE_END
#undef RPCTABLE_CLASS
#undef RPCTABLE_CONTENTS
#undef RPCTABLE_TOOMANYRPCS_STRINGIFY
#undef RPCTABLE_TOOMANYRPCS
As a bonus, specializing tables like this makes it easy to support inheritance.
Imagine we have a ScientificCalculator that inherits from Calculator:
class ScientificCalculator : public Calculator {
public:
double sqrt(double a) {
return std::sqrt(a);
}
};
By separately defining the contents of Calculator, we can reuse that define:
// Separately define the Calculator contents so it can be reused
#define RPCTABLE_CALCULATOR_CONTENTS \
REGISTERRPC(add) \
REGISTERRPC(sub) \
REGISTERRPC(ans)
// Calculator table
#define RPCTABLE_CLASS Calculator
#define RPCTABLE_CONTENTS \
RPCTABLE_CALCULATOR_CONTENTS
#include "RPCGenerate.h"
// ScientificCalculator table
#define RPCTABLE_CLASS ScientificCalculator
#define RPCTABLE_CONTENTS \
RPCTABLE_CALCULATOR_CONTENTS \
REGISTERRPC(sqrt)
#include "RPCGenerate.h"
Transport
We need to define how data will be transported between client and server. Let’s put that in a Transport interface class.
The interface is intentionally left very simple so the application can specify a custom transport . All we need is a method to send, receive, and to close.
namespace cz {
namespace rpc {
class Transport {
public:
virtual ~Transport() {}
// Send one single RPC
virtual void send(std::vector<char> data) = 0;
// Receive one single RPC
// dst : Will contain the data for one single RPC, or empty if no RPC
// available
// return: true if the transport is still alive, false if the transport
// closed
virtual bool receive(std::vector<char>& dst) = 0;
// Close connection to the peer
virtual void close() = 0;
};
} // namespace rpc
} // namespace cz
Result
How should a RPC result look like?
Whenever we make an RPC call, the result can come in 3 forms.
| Form | Meaning |
|---|---|
| Valid | We got a reply from the server with the result value of the RPC call |
| Aborted | The connection failed or was closed, and therefore we don’t have result value |
| Exception | We got a reply from the server with an exception string (The RPC call caused an exception server side) |
namespace cz {
namespace rpc {
class Exception : public std::exception {
public:
Exception(const std::string& msg) : std::exception(msg.c_str()) {}
};
template <typename T>
class Result {
public:
using Type = T;
Result() : m_state(State::Aborted) {}
explicit Result(Type&& val) : m_state(State::Valid), m_val(std::move(val)) {}
Result(Result&& other) {
moveFrom(std::move(other));
}
Result(const Result& other) {
copyFrom(other);
}
~Result() {
destroy();
}
Result& operator=(Result&& other) {
if (this == &other)
return *this;
destroy();
moveFrom(std::move(other));
return *this;
}
// Construction from an exception needs to be separate. so
// RPCReply<std::string> works.
// Otherwise we would have no way to tell if constructing from a value, or
// from an exception
static Result fromException(std::string ex) {
Result r;
r.m_state = State::Exception;
new (&r.m_ex) std::string(std::move(ex));
return r;
}
template <typename S>
static Result fromStream(S& s) {
Type v;
s >> v;
return Result(std::move(v));
};
bool isValid() const {
return m_state == State::Valid;
}
bool isException() const {
return m_state == State::Exception;
};
bool isAborted() const {
return m_state == State::Aborted;
}
T& get() {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
return m_val;
}
const T& get() const {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
return m_val;
}
const std::string& getException() {
assert(isException());
return m_ex;
};
private:
void destroy() {
if (m_state == State::Valid)
m_val.~Type();
else if (m_state == State::Exception) {
using String = std::string;
m_ex.~String();
}
m_state = State::Aborted;
}
void moveFrom(Result&& other) {
m_state = other.m_state;
if (m_state == State::Valid)
new (&m_val) Type(std::move(other.m_val));
else if (m_state == State::Exception)
new (&m_ex) std::string(std::move(other.m_ex));
}
void copyFrom(const Result& other) {
m_state = other.m_state;
if (m_state == State::Valid)
new (&m_val) Type(other.m_val);
else if (m_state == State::Exception)
new (&m_ex) std::string(other.m_ex);
}
enum class State { Valid, Aborted, Exception };
State m_state;
union {
Type m_val;
std::string m_ex;
};
};
// void specialization
template <>
class Result<void> {
public:
Result() : m_state(State::Aborted) {}
Result(Result&& other) {
moveFrom(std::move(other));
}
Result(const Result& other) {
copyFrom(other);
}
~Result() {
destroy();
}
Result& operator=(Result&& other) {
if (this == &other)
return *this;
destroy();
moveFrom(std::move(other));
return *this;
}
static Result fromException(std::string ex) {
Result r;
r.m_state = State::Exception;
new (&r.m_ex) std::string(std::move(ex));
return r;
}
template <typename S>
static Result fromStream(S& s) {
Result r;
r.m_state = State::Valid;
return r;
}
bool isValid() const {
return m_state == State::Valid;
}
bool isException() const {
return m_state == State::Exception;
};
bool isAborted() const {
return m_state == State::Aborted;
}
const std::string& getException() {
assert(isException());
return m_ex;
};
void get() const {
if (!isValid())
throw Exception(isException() ? m_ex : "RPC reply was aborted");
}
private:
void destroy() {
if (m_state == State::Exception) {
using String = std::string;
m_ex.~String();
}
m_state = State::Aborted;
}
void moveFrom(Result&& other) {
m_state = other.m_state;
if (m_state == State::Exception)
new (&m_ex) std::string(std::move(other.m_ex));
}
void copyFrom(const Result& other) {
m_state = other.m_state;
if (m_state == State::Exception)
new (&m_ex) std::string(other.m_ex);
}
enum class State { Valid, Aborted, Exception };
State m_state;
union {
bool m_dummy;
std::string m_ex;
};
};
} // namespace rpc
} // namespace cz
The Result<void> specialization is needed, since for that case there isn’t a result, but the caller still wants to know if the RPC call was properly processed.
Initially, I considered using Expected<T> for RPC replies. But Expected<T> has basically 2 states (Value or Exception), and we need 3 (Value, Exception, and Aborted). One can think that Aborted could be considered an exception, but from a client point of view, it’s not always the case. In some cases you want to know an RPC failed because the connection was closed, and not because the server replied with an exception.
OutProcessor
We need to track ongoing RPC calls so the user code can get the results when they arrive.
Handling a result can be done in two ways. Throught an asynchronous handler (similar to Asio ), or with a future.
Two classes are needed for this. An outgoing processor and a wrapper for a single RPC call.
Another class is needed (Connection) that ties together outgoing and incoming processors. It will be introduced later.
namespace cz {
namespace rpc {
class BaseOutProcessor {
public:
virtual ~BaseOutProcessor() {}
protected:
template <typename R>
friend class Call;
template <typename L, typename R>
friend struct Connection;
template <typename F, typename H>
void commit(Transport& transport, uint32_t rpcid, Stream& data,
H&& handler) {
std::unique_lock<std::mutex> lk(m_mtx);
Header hdr;
hdr.bits.size = data.writeSize();
hdr.bits.counter = ++m_replyIdCounter;
hdr.bits.rpcid = rpcid;
*reinterpret_cast<Header*>(data.ptr(0)) = hdr;
m_replies[hdr.key()] = [handler = std::move(handler)](Stream * in,
Header hdr) {
using R = typename ParamTraits<
typename FunctionTraits<F>::return_type>::store_type;
if (in) {
if (hdr.bits.success) {
handler(Result<R>::fromStream((*in)));
} else {
std::string str;
(*in) >> str;
handler(Result<R>::fromException(std::move(str)));
}
} else {
// if the stream is nullptr, it means the result is being aborted
handler(Result<R>());
}
};
lk.unlock();
transport.send(data.extract());
}
void processReply(Stream& in, Header hdr) {
std::function<void(Stream*, Header)> h;
{
std::unique_lock<std::mutex> lk(m_mtx);
auto it = m_replies.find(hdr.key());
assert(it != m_replies.end());
h = std::move(it->second);
m_replies.erase(it);
}
h(&in, hdr);
}
void abortReplies() {
decltype(m_replies) replies;
{
std::unique_lock<std::mutex> lk(m_mtx);
replies = std::move(m_replies);
}
for (auto&& r : replies) {
r.second(nullptr, Header());
}
};
std::mutex m_mtx;
uint32_t m_replyIdCounter = 0;
std::unordered_map<uint32_t, std::function<void(Stream*, Header)>>
m_replies;
};
template <typename T>
class OutProcessor : public BaseOutProcessor {
public:
using Type = T;
template <typename F, typename... Args>
auto call(Transport& transport, uint32_t rpcid, Args&&... args) {
using Traits = FunctionTraits<F>;
static_assert(
std::is_member_function_pointer<F>::value &&
std::is_base_of<typename Traits::class_type, Type>::value,
"Not a member function of the wrapped class");
Call<F> c(*this, transport, rpcid);
c.serializeParams(std::forward<Args>(args)...);
return std::move(c);
}
protected:
};
// Specialization for when there is no outgoing RPC calls
// If we have no outgoing RPC calls, receiving a reply is therefore an error.
template <>
class OutProcessor<void> {
public:
OutProcessor() {}
void processReply(Stream&, Header) {
assert(0 && "Incoming replies not allowed for OutProcessor<void>");
}
void abortReplies() {}
};
} // namespace rpc
} // namespace cz
The entry point to start an RPC call is the OutProcessor<T>::call method. That packs together the data in a Call object. We can then use that object to set the result handling.
The reason for separating calls with a processor and a call object, is to make it easier for the user to specify the handling.
In other words… The user code asks the processor to prepare an RPC call, then specifies how to handle the result (which triggers the send).
The abortReplies method is called one single time when the transport is closed, so the user code gets the abort notifications for any RPCs that are waiting for a result.
The OutProcessor<void> specialization will come in handy later, as we deal with bidirectional RPCS.
The source code for the Call class used by the OutProcessor:
namespace cz {
namespace rpc {
class BaseOutProcessor;
template <typename F>
class Call {
private:
using RType = typename FunctionTraits<F>::return_type;
using RTraits = typename ParamTraits<RType>;
public:
Call(Call&& other)
: m_outer(other.m_outer)
, m_transport(other.m_transport)
, m_rpcid(other.m_rpcid)
, m_data(std::move(other.m_data)) {}
Call(const Call&) = delete;
Call& operator=(const Call&) = delete;
Call& operator=(Call&&) = delete;
~Call() {
if (m_data.writeSize() && !m_commited)
async([](Result<RTraits::store_type>&) {});
}
template <typename H>
void async(H&& handler) {
m_outer.commit<F>(m_transport, m_rpcid, m_data,
std::forward<H>(handler));
m_commited = true;
}
std::future<typename Result<typename RTraits::store_type>> ft() {
auto pr = std::make_shared<std::promise<Result<RTraits::store_type>>>();
auto ft = pr->get_future();
async([pr = std::move(pr)](Result<RTraits::store_type> && res) {
pr->set_value(std::move(res));
});
return ft;
}
protected:
template <typename T>
friend class OutProcessor;
explicit Call(BaseOutProcessor& outer, Transport& transport, uint32_t rpcid)
: m_outer(outer), m_transport(transport), m_rpcid(rpcid) {
m_data << uint64_t(0); // rpc header
}
template <typename... Args>
void serializeParams(Args&&... args) {
serializeMethod<F>(m_data, std::forward<Args>(args)...);
}
BaseOutProcessor& m_outer;
Transport& m_transport;
uint32_t m_rpcid;
Stream m_data;
// Used in the destructor to do a commit with an empty handler if the rpc
// was not committed.
bool m_commited = false;
};
} // namespace rpc
} // namespace cz
Note that OutProcessor<T> doesn’t need a reference/pointer to an object of T. It only needs to know the type we are sending the RPCs to, so it knows what Table<T> to use.
This is an example how to use the OutProcessor:
//
// "trp" is a transport that sends data to a "Calculator" server
void testOutProcessor(Transport& trp) {
// A processor that calls RPCs on a "Calculator" server
OutProcessor<Calculator> outPrc;
// Handle with an asynchronous handler
outPrc.call<decltype(&Calculator::add)>(
trp, (int)Table<Calculator>::RPCId::add, 1.0, 2.0)
.async([](Result<double> res) {
printf("%2.0f\n", res.get()); // prints '3'
});
// Handle with a future
Result<double> res = outPrc.call<decltype(&Calculator::add)>(
trp, (int)Table<Calculator>::RPCId::add, 1.0, 3.0)
.ft().get();
printf("%2.0f\n", res.get()); // prints '4'
}
Again, a bit verbose, since I haven’t introduced all the code that wraps things up. But shows how the OutProcessor<T> and Call interfaces work.
The std::future implementation simply builds on the asynchronous implementation.
InProcessor
Now that we can send an RPC and wait for the result, let’s look at what we need to do on the other side. What to do when an RPC call is received on the server.
Let’s create a InProcessor<T> class.
Contrary to OutProcessor<T>, InProcessor<T> needs to keep a reference to an object of type T. This is so when an RPC is received, it can call the requested method on that object, and send the result back to the client.
namespace cz {
namespace rpc {
class BaseInProcessor {
public:
virtual ~BaseInProcessor() {}
};
template <typename T>
class InProcessor : public BaseInProcessor {
public:
using Type = T;
InProcessor(Type* obj, bool doVoidReplies = true)
: m_obj(*obj), m_voidReplies(doVoidReplies) {}
void processCall(Transport& transport, Stream& in, Header hdr) {
Stream out;
// Reuse the header as the header for the reply, so we keep the counter
// and rpcid
hdr.bits.size = 0;
hdr.bits.isReply = true;
hdr.bits.success = true;
auto&& info = Table<Type>::get(hdr.bits.rpcid);
#if CZRPC_CATCH_EXCEPTIONS
try {
#endif
out << hdr; // Reserve space for the header
info->dispatcher(m_obj, in, out);
#if CZRPC_CATCH_EXCEPTIONS
} catch (std::exception& e) {
out.clear();
out << hdr; // Reserve space for the header
hdr.bits.success = false;
out << e.what();
}
#endif
if (m_voidReplies || (out.writeSize() > sizeof(hdr))) {
hdr.bits.size = out.writeSize();
*reinterpret_cast<Header*>(out.ptr(0)) = hdr;
transport.send(out.extract());
}
}
protected:
Type& m_obj;
bool m_voidReplies = false;
};
template <>
class InProcessor<void> {
public:
InProcessor(void*) {}
void processCall(Transport&, Stream&, Header) {
assert(0 && "Incoming RPC not allowed for void local type");
}
};
} // namespace rpc
} // namespace cz
The CZRPC_CATCH_EXCEPTIONS define allows us to tweak if we want server side exceptions to be passed to the clients.
It’s the use of InProcessor<T> (and Table<T>) that allows calling RPCs on objects that don’t know anything about RPCs or network. For example, consider this dummy example:
void calculatorServer() {
// The object we want to use for RPC calls
Calculator calc;
// The server processor. It will call the appropriate methods on 'calc' when
// an RPC is received
InProcessor<Calculator> serverProcessor(&calc);
while (true) {
// calls to serverProcessor::processCall whenever there is data
}
}
The Calculator object used for RPCs doesn’t know anything about RPCs. The InProcessor<Calculator> does all the required work. This makes it possible use third party classes for RPCs.
In some situations, we do want have the class used for RPCs to know about RPCs and/or network. For example, if you’re creating a chat system, you have the clients sending messages (RPC calls) to the server. The server needs to know what clients are connected, so it can broadcast messages.
Connection
We can now send and receive RPCs, although with a bit of a verbose API. The OutProcessor<T> and InProcessor<T> template classes deal with what happens to data at both ends of the connection.
So, what we need now is exactly that. A Connection to tie in one place everything needed to send and receive data, and simplify the API.
namespace cz {
namespace rpc {
struct BaseConnection {
virtual ~BaseConnection() {}
//! Process any incoming RPCs or replies
// Return true if the connection is still alive, false otherwise
virtual bool process() = 0;
};
template <typename LOCAL, typename REMOTE>
struct Connection : public BaseConnection {
using Local = LOCAL;
using Remote = REMOTE;
using ThisType = Connection<Local, Remote>;
Connection(Local* localObj, std::shared_ptr<Transport> transport)
: localPrc(localObj), transport(std::move(transport)) {}
template <typename F, typename... Args>
auto call(Transport& transport, uint32_t rpcid, Args&&... args) {
return remotePrc.template call<F>(transport, rpcid,
std::forward<Args>(args)...);
}
static ThisType* getCurrent() {
auto it = Callstack<ThisType>::begin();
return (*it) == nullptr ? nullptr : (*it)->getKey();
}
virtual bool process() override {
// Place a callstack marker, so other code can detect we are serving an
// RPC
typename Callstack<ThisType>::Context ctx(this);
std::vector<char> data;
while (true) {
if (!transport->receive(data)) {
// Transport is closed
remotePrc.abortReplies();
return false;
}
if (data.size() == 0)
return true; // No more pending data to process
Header hdr;
Stream in(std::move(data));
in >> hdr;
if (hdr.bits.isReply) {
remotePrc.processReply(in, hdr);
} else {
localPrc.processCall(*transport, in, hdr);
}
}
}
InProcessor<Local> localPrc;
OutProcessor<Remote> remotePrc;
std::shared_ptr<Transport> transport;
};
} // namespace rpc
} // namespace cz
This puts together the output processor, the input processor, and the transport.
To make it possible for user code to detect if it's in the middle of serving an RPC, it uses a class I introduced in an earlier post. The Callstack class.
This allows the creation of RPC/network aware code if necessary, like server classes.
So, how this simplifies the API ?
Since the Connection<T> has everything we need, one macro taking as parameters the connection object, a function name and the parameters, does everything, including type checks so it doesn’t compile if it’s an invalid call.
#define CZRPC_CALL(con, func, ...) \
(con).call<decltype(&std::decay<decltype(con)>::type::Remote::func)>( \
*(con).transport, \
(uint32_t)cz::rpc::Table< \
std::decay<decltype(con)>::type::Remote>::RPCId::func, \
##__VA_ARGS__)
Using this macro, RPC calls syntax is surprisingly simple. For example, consider this client code:
// Some class to use for RPC calls
class MagicSauce {
public:
int func1(int a, int b) {
return a + b;
}
int func2(int a, int b) {
return a + b;
}
};
// Define RPC table for MagicSauce
#define RPCTABLE_CLASS MagicSauce
#define RPCTABLE_CONTENTS REGISTERRPC(func1)
#include "RPCGenerate.h"
// 'trp' is a fully functional transport
void test_Connection(std::shared_ptr<Transport> trp) {
Connection<void, MagicSauce> con(nullptr, trp);
// Doesn't compile : Invalid number of parameters
// CZRPC_CALL(con, func1, 1);
// Doesn't compile : Wrong type of parameters
// CZRPC_CALL(con, func1, 1, "hello");
// Doesn't compile: func3 is not a MagicSauce method
// CZRPC_CALL(con, func3, 1, 2);
// Doesn't compile: func2 is a method of MagicSauce, but not registered as
// RPC
// CZRPC_CALL(con, func2, 1, 2);
// Compiles fine, since everything is valid
CZRPC_CALL(con, func1, 1, 2).async([](Result<int> res) {
printf("%d\n", res.get()); // print '3'
});
}
Notice the void and nullptr used when creating the connection with Connection<void, MagicSauce> con(nullptr, trp); ?
This accommodates for bidirectional RPCs (the server can also call RPCs on a client). In this case, we don’t expect client side RPCs, so the client side Connection object doesn’t have a local object to call RPCs on.
A simplified example (not functional) of bidirectional RPCs can be something like this:
class ChatClient;
class ChatServer {
public:
// Called by clients to post new messages
void msg(const char* msg);
void addNewClient(std::shared_ptr<Transport> trp);
private:
// Connection specifies both a LOCAL, and REMOTE object types
std::vector<std::unique_ptr<Connection<ChatServer, ChatClient>>> m_clients;
};
#define RPCTABLE_CLASS ChatServer
#define RPCTABLE_CONTENTS REGISTERRPC(msg)
#include "RPCGenerate.h"
class ChatClient {
public:
void onMsg(const char* msg);
};
#define RPCTABLE_CLASS ChatClient
#define RPCTABLE_CONTENTS REGISTERRPC(onMsg)
#include "RPCGenerate.h"
void ChatServer::msg(const char* msg) {
// Simply broadcast the message to all clients
for (auto&& c : m_clients) {
CZRPC_CALL(*c, onMsg, msg);
}
}
void ChatServer::addNewClient(std::shared_ptr<Transport> trp) {
auto con = std::make_unique<Connection<ChatServer, ChatClient>>(this, trp);
m_clients.push_back(std::move(con));
}
void ChatClient::onMsg(const char* msg) {
printf("%s\n", msg);
}
void test_ChatServer() {
ChatServer server;
while (true) {
// Wait for connections, and call ChatServer::addClient
}
}
// 'trp' is some fully functional transport connected to the ChatServer
void test_ChatClient(std::shared_ptr<Transport> trp) {
ChatClient client;
// In this case, we have a client side object to answer RPCs
Connection<ChatClient, ChatServer> con(&client, trp);
while (true) {
// call the 'msg' RPC whenever the user types something, like this:
CZRPC_CALL(con, msg, "some message");
// The server will call our client 'onMsg' when other clients send a
// message
}
}
The Connection template parameters in the server and client are reversed. Whenever data is received, the Connection object forwards processing to the InProcessor if it’s an incoming RPC call (to call on our side), or to the OutProcessor if it’s a reply to a previous outgoing RPC call. Data flow for bidirectional RPCs looks like this:
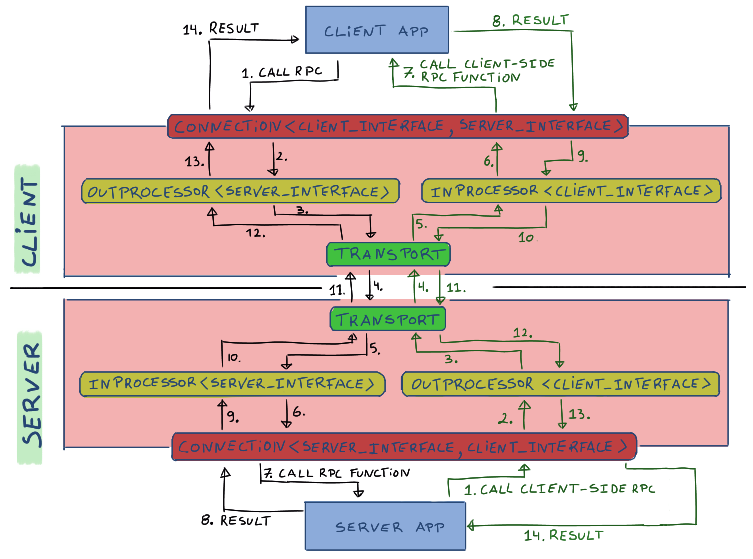
Improvements
A couple of things were left out of the framework intentionally, so the application can decide what’s best. For example:
- Transport initialization
- The transport interface is very simple, so it doesn’t impose any specific way of initialization or detecting incoming data. It’s up to the application to provide a fully functional and connected transport to the
Connectionclass. This is also the reason why I avoided showing any transport initialization, since I would have to present a fully functional transport implementation for that. - At the time of writing, the source code repository has one transport implementation using Boost Asio (or standalone Asio)
- The transport interface is very simple, so it doesn’t impose any specific way of initialization or detecting incoming data. It’s up to the application to provide a fully functional and connected transport to the
- Disconnection detection
- As with initialization, there is minimal code for dealing with or detecting shutdowns. It is up to the application to decide how to do this with whatever custom transports it provides.
- At some point I had support for server side functions that return std::futures. But as I was writing this article I removed that to simplify things. That will be added back to the repository soon, since I need it for my own projects.
- This is needed to support wrapping classes whose API returns std::future instances. Say you have a
Loginserver class with aloginmethod. Thatloginmethod is in itself probably asynchronous (returns a std::future) since you’ll be checking a database for the login details. - It’s not particularly hard to implement, but it has one niggle I couldn’t get rid of without introducing a lot more code. The bulk of the changes would be in the
InProcessor<T>class. It would have to keep track of ongoing calls whosestd::future<T>instances are not ready yet. The problem here is how wouldInProcessor<T>detect when those futures are ready so it can send the result back to the client? I can think of two approaches:- Regular polling all pending std::futures to see if they are ready.
- Use continuations (
std::future::then), which are not available in the standard yet. That would be the easiest solution.InProcessor<T>would set a continuation to send the result back to the client whenever it is ready. No need for polling anything.
- This would affect no client side code whatsoever. Say a server side function returns
std::future<bool>. All the client sees and needs is still just aResult<bool>.
- This is needed to support wrapping classes whose API returns std::future instances. Say you have a
Final words
Feel free to nitpick at the code. This amount of code certainly needs a couple of fresh pair of eyes (and brain). Although any major changes will only go into the source code repository, and not this article.
After a short poll on Twitter https://twitter.com/RuiMVFigueira, it seems the next article will be about cache friendly ticking.
I’ll be explaining and sharing some self-contained code I use in my project to tick a couple of things (in-game computers included).
I will have to measure performance, but hopefully it should be more cache friendly than the classic ticking. I’ll share the results either way.
Still, the code is useful as-is even if it turns out it’s not improving performance that much.
Subscribe to the newsletter to get a notification when a new technical article is up, and/or follow me on twitter https://twitter.com/RuiMVFigueira .
License
The license for the code in this article can be found at https://bitbucket.org/ruifig/czrpc
Hi Rui,
great work, thanks for sharing!
However, it looks like there’s a lot of manual work to define new interfaces (using those horrible macros, and the include approach), and equally a lot to define new “rpc-able” types (even aggregates of existing ones), since you don’t really have a reflection system.
Consequently I do think that having a little data definition language and generating code from it is a vastly superior approach, since you get:
no manual error-prone work for defining new interfaces (e.g. forgot to specify a method in the table).
no need to manually write serializers/deserializers for aggregated types.
trivial cross-language support, by generating matching code.
and very importantly superior compilation time since you don’t have to rely on all that heavy templated code.
A final nitpick note on the code: your usage of bitfields in the Bits structure is dangerous and could easily fail on other compilers, since you’re dividing a bitfield between multiple fields of potentially different types (and alignments).
In your case “uint32_t” and “unsigned” luckily share the same size and alignment so there’s no padding between them and Visual C++ would still pack them as expected even if you didn’t use exactly 32 bits for your first bitfield.
Hi Tim,
Glad you liked it.
And thank you for your feedback.
The approach I was using for the most part of 2-3 years on my project was somewhat similar to what you mention, although without a data definition language, since I rely heavily on custom types.
Given for example all the classes I’m using for servers, I would add tags the methods I wanted for RPC calls (changing the classes), and as part of the build, a clang based tool would analyze all RPC related classes and methods, and generate a “Client” counterpart of any Server classes, with an interface matching the server class. It would also generate serialization code for any types I wished.
I was happy with how it worked, but was curious how could I push it with modern C++ while still avoiding code generation.
For this one I wanted to focus on non-intrusive framework. I don’t need to change the class that is being used for RPCs.
Also, if I forget to add a method to the table, it will fail to compile if I try to use that method.
Right now, I’m inclined to use this framework since it can be used as-is without code generation, but I can also plug in on top code generation to serialize aggregated types.
The table macros don’t bother me much to be honest. Doesn’t require any more typing than a data definition language, and no need to specify any parameters. Just the method name. Although it’s ugly I know. 🙂
I see advantages and disadvantages with both.
Pros of the previous solution:
– Automatic generation of a client class matching the server class (plus an extra parameter for the async handler)
– Automatic generation of serialization code
– Better compile times
Cons of the previous solution:
– Clang/LLVM dependency was like concrete boots. Hard to keep updated. The version of Clang I was using was starting to actually lag behind VS, so it wouldn’t parse all my code without putting #ifdefs here and there. Was just another thing to maintain.
– Also, compiling on a different platform required me to also have the parser running on that platform (not mandatory, but nice for building from a clean slate).
– Intrusive. Needed to change classes I wanted to use for RPCs. Also, those classes needed to inherit from an RPCServer class. They were by design RPC-aware.
Pros of this solution:
– Non-intrusive
– No dependencies
– Acceptable API, considering no code generation required.
– Code generation can be applied on top if required.
– Possible to use any type for RPC parameters (provided we have the ParamTrait for that type of course)
Cons of this solution
– Ugly macros.
– Worse compile times.
– No code generation whatsoever as-is.
We use Thrift heavily at work too. And we end up using just a compact binary protocol with C++ only. While I understand the value in Thrift’s approach, to support different protocols, transports, cross-language, etc, it is pretty much dead-weight (albeit not necessarily runtime penalty) if you don’t need all that.
I thought a pure binary and C++ only would be the best approach for my personal projects.
Regarding the Header class… Yeah, I missed that one. Thanks. 🙂
I’ll revise it.
A big portion of the framework was created simultaneously with the article. Things got hard to juggle sometimes.
For example, the Reply class was literally created after most of the article was complete. I was using a different approach initially. Had to go over the entire article again. Wouldn’t be surprised there are a couple of more mistakes.
Although the repository does have some minimal unit tests.
Thanks again for the feedback. Much appreciated.
Just a small update…
Not sure I agree this approach requires more typing. Having a separate data definition file would actually require more typing in my opinion.
Its just that a data definition file provides a clean separation of things. Tidier.
The macros are ugly, but short and embedded in the code. No tools necessary. Put a table specialization (or all of them) in a separate header file (just for the specializations), and you pretty much have the same result as a data definition file. Trade-offs as usual.
Although I still agree on the serialization code.
Fixed the Header class.
Just noticed I do have a static_assert there to make sure it has the right size. 🙂
Any unexpected padding would have caused that static_assert to trigger. Defensive programming. 🙂
This is nice and quite short actually! We use the same techniques for performing RPC in the libqi framework, like the generic serialization methods or the macros to register object interfaces in the type system. It is FOSS – https://github.com/aldebaran/libqi – and under the BSD license.
Hi Victor,
Never heard of libqi. I’ll take a look.
I’ve been making improvements to the framework, so its deviating from the article. But still provided me a good foundation. 🙂
Take a look at the short post about generic RPCs.
I will be submiting lots of changes to the repository soon.
Thanks for dropping by.
This is a good effort. How easy / difficult it is to integrate this mechanism with the gRPC as the serialization component (to remove the protobuffers)?
gRPC has good routing and other features – but it is bad with the protobuf requirement. By replacing the protobuf serialization with this auto-deducted typesafe serialization, it would combine best of both worlds.
GK
http://gk.palem.in/
Hi Gopalakrishna. Welcome to the blog.
I’m afraid I never used gRPC, so can’t tell you on the spot how easy/hard it would be.
I just took a quick look at gRPC’s website, and it seems it follows the typical RPC framework flow? Some files with service definitions, and support for several programming languages?
czRPC is meant for C++ only, and binary encoding, so I’d say it targets different needs.
If you intend to use gRPC with C++ only, then maybe it’s worth taking a look.
But like I mentioned before, some people do prefer having separate service definition files.
I’ve been working on improvements to czRPC, but they are not available in the main repository.
If you want to keep an eye on it, either subscribe to my mailing list, or check out my Patreon Page ( https://www.patreon.com/RuiMVFigueira ). For the mailing list, I send out an email only for new articles or significant improvements to my open source projects.